
Showing posts with label tools. Show all posts
Showing posts with label tools. Show all posts
Wednesday, October 28, 2009
Tuesday, June 23, 2009
Friday, June 5, 2009
1st Law Of Cybernetics:
"The unit
[which can be a person]
within the system
[which can be a situation or an organisation]
which has the most behavioural responses available to it
controls the system"
[which can be a person]
within the system
[which can be a situation or an organisation]
which has the most behavioural responses available to it
controls the system"
Friday, May 1, 2009
Wolfram on Wolfram Alfa
March 5, 2009
"Some might say that Mathematica and A New Kind of Science are ambitious projects.
But in recent years I’ve been hard at work on a still more ambitious project—called Wolfram|Alpha.
And I’m excited to say that in just two months it’s going to be going live:
Mathematica has been a great success in very broadly handling all kinds of formal technical systems and knowledge.

But what about everything else? What about all other systematic knowledge? All the methods and models, and data, that exists?
Fifty years ago, when computers were young, people assumed that they’d quickly be able to handle all these kinds of things and that one would be able to ask a computer any factual question, and have it compute the answer.
But it didn’t work out that way. Computers have been able to do many remarkable and unexpected things. But not that.
I’d always thought, though, that eventually it should be possible. And a few years ago, I realized that I was finally in a position to try to do it.
I had two crucial ingredients: Mathematica and NKS. With Mathematica, I had a symbolic language to represent anything—as well as the algorithmic power to do any kind of computation. And with NKS, I had a paradigm for understanding how all sorts of complexity could arise from simple rules.
But what about all the actual knowledge that we as humans have accumulated?
A lot of it is now on the web—in billions of pages of text. And with search engines, we can very efficiently search for specific terms and phrases in that text.
But we can’t compute from that. And in effect, we can only answer questions that have been literally asked before. We can look things up, but we can’t figure anything new out.
So how can we deal with that? Well, some people have thought the way forward must be to somehow automatically understand the natural language that exists on the web. Perhaps getting the web semantically tagged to make that easier.
But armed with Mathematica and NKS I realized there’s another way: explicitly implement methods and models, as algorithms, and explicitly curate all data so that it is immediately computable.
It’s not easy to do this. Every different kind of method and model—and data—has its own special features and character. But with a mixture of Mathematica and NKS automation, and a lot of human experts, I’m happy to say that we’ve gotten a very long way.
How can I say it?
"But, OK. Let’s say we succeed in creating a system that knows a lot, and can figure a lot out. How can we interact with it?
The way humans normally communicate is through natural language. And when one’s dealing with the whole spectrum of knowledge, I think that’s the only realistic option for communicating with computers too.
Of course, getting computers to deal with natural language has turned out to be incredibly difficult. And for example we’re still very far away from having computers systematically understand large volumes of natural language text on the web.
But if one’s already made knowledge computable, one doesn’t need to do that kind of natural language understanding.
All one needs to be able to do is to take questions people ask in natural language, and represent them in a precise form that fits into the computations one can do.
Of course, even that has never been done in any generality. And it’s made more difficult by the fact that one doesn’t just want to handle a language like English: one also wants to be able to handle all the shorthand notations that people in every possible field use.
I wasn’t at all sure it was going to work. But I’m happy to say that with a mixture of many clever algorithms and heuristics, lots of linguistic discovery and linguistic curation, and what probably amount to some serious theoretical breakthroughs, we’re actually managing to make it work.
Neverending trillions
"Pulling all of this together to create a true computational knowledge engine is a very difficult task.
It’s certainly the most complex project I’ve ever undertaken. Involving far more kinds of expertise—and more moving parts—than I’ve ever had to assemble before.
And—like Mathematica, or NKS—the project will never be finished.
But I’m happy to say that we’ve almost reached the point where we feel we can expose the first part of it.
It’s going to be a website: www.wolframalpha.com. With one simple input field that gives access to a huge system, with trillions of pieces of curated data and millions of lines of algorithms.
We’re all working very hard right now to get Wolfram|Alpha ready to go live.
I think it’s going to be pretty exciting. A new paradigm for using computers and the web.
That almost gets us to what people thought computers would be able to do 50 years ago!
Due Soon: Wolfram Alpha
Wolfram Alpha is an answer-engine developed by the international company Wolfram Research. The service will be an online computational data engine based on intuitive query parsing, a large library of algorithms, and A New Kind of Science approach to answering queries.[1] It was announced in March 2009 by British physicist Stephen Wolfram, to be launched in May 2009.
Wolfram Alpha differs from search engines in that it does not simply return a list of results based on a keyword, but instead computes answers and relevant visualizations from a collection of known information. Other new search engines, known collectively as semantic search engines, have developed alpha applications of this type, which index a large amount of answers, and then try to match the question to one. Examples of companies using this strategy include True Knowledge, and Microsoft's Powerset.
Wolfram Alpha has many parallels with Cyc, a project aimed at developing a common-sense inference engine since the 80s, though without producing any major commercial application. Cyc founder Douglas Lenat was one of the few given an opportunity to test Wolfram Alpha before its release:
It handles a much wider range of queries than Cyc, but much narrower than Google; it understands some of what it is displaying as an answer, but only some of it ... The bottom line is that there are a large range of queries it can't parse, and a large range of parsable queries it can't answer
-Douglas Lenat[2]
Wolfram's earlier flagship product Mathematica encompasses computer algebra, numerical computation, visualization and statistics capabilities and can be used on all kinds of mathematical analysis, from simple plotting to signal processing, but will not be included in the alpha release, due to computation-time problems.[3]
Tuesday, January 6, 2009


Monday, December 1, 2008
Novas regras para atendimento
Entra em vigor hoje a portaria que regulamenta o decreto presidencial 6.523, de 31 de julho, que estabeleceu novas regras para atendimento, em setores regulados:
Veja abaixo as regras:
Poderá haver interrupção do acesso ao SAC quando o serviço ofertado não estiver disponível para contratação.
O que mudou
- energia elétrica,
- telefonia,
- televisão por assinatura,
- planos de saúde,
- aviação civil,
- empresas de ônibus,
- bancos e cartões de crédito fiscalizados pelo Banco Central.
Veja abaixo as regras:
Tempo de espera
A regra geral é que o consumidor não espere mais do que um minuto até o contato direto com o atendente, quando essa opção for selecionada.Casos específicos
Energia Elétrica - segue a regra geral de, no máximo, um minuto de espera. O tempo de atendimento só poderá ser maior no caso de atendimento emergencial que implique a interrupção do fornecimento de energia elétrica a um grande número de consumidores, provocando elevada concentração de chamadas.Horário de funcionamento
A regra geral é o funcionamento durante 24 horas, sete dias por semana. O texto garante o acesso do consumidor ao fornecedor sempre que o serviço esteja sendo oferecido ou possa ser contratado pelo consumidor.Poderá haver interrupção do acesso ao SAC quando o serviço ofertado não estiver disponível para contratação.
O que mudou
- A empresa deve garantir, no primeiro menu eletrônico e em todas suas subdivisões, o contato direto com o atendente.
- Sempre que oferecer menu eletrônico, as opções de reclamações e de cancelamento têm de estar entre as primeiras alternativas.
- No caso de reclamação e cancelamento, fica proibida a transferência de ligação. Todos os atendentes deverão ter atribuição para executar essas funções.
- As reclamações terão que ser resolvidas em até cinco dias úteis. O consumidor será informado sobre a resolução de sua demanda.
- O pedido de cancelamento de um serviço será imediato.
- Deve ser oferecido ao consumidor um único número de telefone para acesso ao atendimento.
- Fica proibido, durante o atendimento, exigir a repetição da demanda do consumidor.
- Ao selecionar a opção de falar com o atendente, o consumidor não poderá ter sua ligação finalizada sem que o contato seja concluído.
- Só é permitida a veiculação de mensagens publicitárias durante o tempo de espera se o consumidor permitir.
- O acesso ao atendente não poderá ser condicionado ao prévio fornecimento de dados pelo consumidor.
- O cidadão que não receber o atendimento adequado poderá denunciar ao Sistema Nacional de Defesa do Consumidor (SNDC), Ministérios Públicos, Procons, Defensorias Públicas e entidades civis que representam a área.
Thursday, November 27, 2008

Monday, November 24, 2008
Fighting with photons
Oct 30th 2008 From The Economist print edition
LIKE so much else in science fiction, the ray gun was invented by H.G. Wells. In the tentacles of Wells’s Martians it was a weapon as unanswerable by earthlings as the Maxim gun in the hands of British troops was unanswerable by Africans. Science fiction, though, it has remained. Neither hand-held pistols nor giant, orbiting anti-missile versions of the weapon have worked. But that is about to change. The first serious battlefield ray gun is now being deployed. And the next generation, now in the laboratory, is coming soon.
LIKE so much else in science fiction, the ray gun was invented by H.G. Wells. In the tentacles of Wells’s Martians it was a weapon as unanswerable by earthlings as the Maxim gun in the hands of British troops was unanswerable by Africans. Science fiction, though, it has remained. Neither hand-held pistols nor giant, orbiting anti-missile versions of the weapon have worked. But that is about to change. The first serious battlefield ray gun is now being deployed. And the next generation, now in the laboratory, is coming soon.
The deployed ray gun (or “directed-energy weapon”, in the tedious jargon that military men seem compelled to use to describe technology) is known as Zeus. It is not designed to kill. Rather, its purpose is to allow you to remain at a safe distance when you detonate unexploded ordnance, such as the homemade roadside bombs that plague foreign troops in Iraq.
This task now calls for explosives. In practice, that often means using a rocket-propelled grenade, so as not to expose troops to snipers. But rockets are expensive, and sometimes miss their targets. Zeus is effective at a distance of 300 metres, and a laser beam, unlike a rocket, always goes exactly where you point it.
Only one god
At the moment, there is only one Zeus in the field. It is sitting in the back of a Humvee in an undisclosed theatre of war. But if it proves successful it will, according to Scott McPheeters of the American army’s Cruise Missile Defence Systems Project Office for Directed Energy Applications, be joined by a dozen more within a year.
If Zeus works, it will make soldiers’ lives noticeably safer. But what would really make a difference would be the ability to destroy incoming artillery rounds. The Laser Area Defence System, LADS, being developed by Raytheon, is intended to do just that—blowing incoming shells and small rockets apart with laser beams. The targets are tracked by radar and (if they are rockets) by infrared sensors. When they come within range, they are zapped.
If it works, LADS will be a disruptive technology in more senses than one. It will probably supersede Raytheon’s Phalanx system, which uses mortars to do the same thing. Phalanx and its competitors require lots of ammunition, and can be overwhelmed by heavy barrages. By contrast, Mike Booen, vice-president of Advanced Missile Defence and Directed Energy Weapons at Raytheon, observes, as long as LADS is supplied with electricity it has “an infinite magazine”.
And LADS is merely the most advanced of a group of anti-artillery lasers under development. Though Raytheon is convinced it is on to a winner and is paying for most of the development costs out of its own pocket, it has received some money from the Directed Energy Weapons Programme Office of the American navy. In August, inter-service rivalry reared its head, when the army handed Boeing a $36m contract to develop a similar weapon, known at the moment as the High Energy Laser Technology Demonstrator.
The army’s Space and Missile Defence Command is also in the game. Its Joint High Power Solid State Laser, a prototype of which should be ready next summer, is meant to destroy rockets the size of the Katyushas used by insurgents in Afghanistan and Iraq, and by Hizbullah in Lebanon.
The most ambitious laser project of all, though, is the Airborne Laser, or ABL, being developed by the American Missile Defence Agency and Boeing, Lockheed Martin and Northrop Grumman. The beam is generated by mixing chemicals in a reactor known as a COIL (chemical oxygen iodine laser) and packs a far bigger punch than the electrically generated beams emitted by systems such as LADS. When mounted in the nose-cone of a specially converted Boeing 747, an ABL should be capable of disabling a missile from a distance of several hundred kilometres.
The aim is to hit large ballistic missiles, including ICBMs, just after they are launched—in the boost phase. The ABL is therefore a son of Ronald Reagan’s Star Wars scheme, although in that programme, which dates back to the 1980s, the lasers would have operated from space.
There are many advantages to attacking a missile during its boost phase. First, it is still travelling slowly, so it is easier to hit. Second, it is easy to detect because of its exhaust plume (once the boost phase is over, the engine switches off and the missile follows Newton’s law of gravity to its target). Third, if it has boosters that are designed to be jettisoned, it will be a larger target when it is launched. Fourth, any debris will fall on those who launched it, rather than those at whom it was aimed.
Getting the system to work in practice will be hard, though. A missile launch is observed using an infrared detector. Then the missile must be tracked. When the beam fires, the control system must compensate both for aircraft jitter and for distortions in the beam’s path caused by atmospheric conditions. And ABL-carrying planes must be in the right place at the right time in the first place. Even so, a number of tests have been carried out, and according to Colonel Robert McMurry, the head of the Airborne Laser Programme Office at Kirtland Air Force Base in New Mexico, there will be a full-scale attempt to shoot down a boost-phase missile off the coast of California next summer. 
All of which is good news, at least for countries able to deploy the new hardware. But wars are not won by defence alone. What people in the business are more coy about discussing is the offensive use of lasers. At least one such system is under development, though. The aeroplane-mounted Advanced Tactical Laser, or ATL, another chemical laser being put together by Boeing and the American air force, is designed to “neutralise” targets on the ground from a distance of several kilometres. Targeting data will be provided by telescopic cameras on the aircraft, by pictures from satellites and unmanned aerial drones, and by human target-spotters on the ground. The question is: what targets?
The ATL’s supporters discuss such possibilities as disabling vehicles by destroying their wheels and disrupting enemy communications by severing telephone lines. Killing troops is rarely mentioned. However, John Pike, the director of GlobalSecurity.org, a military think-tank in Alexandria, Virginia, who is an expert on ATL, says its main goal is, indeed, to kill enemy combatants.
Surely this is forbidden?
Boeing is unwilling to discuss the matter and John Wachs, the head of the Space and Missile Defence Command’s Directed Energy Division, observes that it is “politically sensitive”. The public may have misgivings about a silent and invisible weapon that would boil the body’s fluids before tearing it apart in a burst of vapour.
That seems oddly squeamish, though. War is not a pleasant business. It is doubtful that being burst by a laser is worse than being hit by a burst from a machine gun. As the Sudanese found out at the Battle of Omdurman in 1898, the year that “The War of the Worlds” was published, that is pretty nasty too.
Bedtime stories go online
Jemima Kiss, guardian.co.uk,
Thursday November 20 2008 12.17 GMT
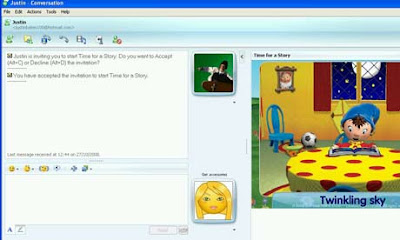

Noddy on Windows Live Messenger: Mr Men and Paddington Bear are also set to be adapted for the tool
Thursday November 20 2008 12.17 GMT

Noddy on Windows Live Messenger: Mr Men and Paddington Bear are also set to be adapted for the tool
Bedtime stories may never be the same after the launch of an online tool to let parents and children who cannot be together share classic tales.
Built by entertainment company Chorion for the Noddy stories, Time for a Story lets parents and grandparents contact a child through Windows Live Messenger and lead them through a digital version of stories about the character.
Chorion is initially releasing three Noddy stories through the application, with more planned. Mr Men and Paddington Bear are also scheduled to be adapted for the tool – although they may target at an older age group than the two- to five-year-olds Noddy is aimed at.
It is thought grown-ups in their 30s may also sign up for a dose of nostalgia based around their favourite childhood characters.
Time for a Story, developed by agency Digital Outlook, is being promoted through the Mumsnet community website, which took part in a trial of the application, and also on the MSN website, which gives a demonstration of the tool.
Users in the UK can access the stories through the "activities" tab in Windows Live Messenger. Parents control the speed of the story by clicking through pages, while the child can interact with pictures and words on screen for each part of the story.
"The kernel of the idea was from a producer who was working late a lot and not getting home to speak to his child, and ended up talking to them through IM," said a Chorion spokeswoman.
"There's no way we're saying this should replace that one-to-one contact or reading to a child while you are there, but we are trying to create a tool that allows parents or grandparents to interact with the child in a meaningful way when they can't be there."
The spokeswoman added that the tool provided a structure to the conversation through the form of the story – which would allow even very young children to benefit, and because instant messenger enables video chat it provided an emotional connection.
Thursday, November 13, 2008
Aplicações do Google Insights - 1
|

2
|

3
|




Google Uses Searches to Track Flu’s Spread
That simple act, multiplied across millions of keyboards in homes around the country, has given rise to a new early warning system for fast-spreading flu outbreaks, called Google Flu Trends.
Tests of the new Web tool from Google.org, the company’s philanthropic unit, suggest that it may be able to detect regional outbreaks of the flu a week to 10 days before they are reported by the Centers for Disease Control and Prevention.
In early February, for example, the C.D.C. reported that the flu cases had recently spiked in the mid-Atlantic states. But Google says its search data show a spike in queries about flu symptoms two weeks before that report was released. Its new service at google.org/flutrends analyzes those searches as they come in, creating graphs and maps of the country that, ideally, will show where the flu is spreading.
The C.D.C. reports are slower because they rely on data collected and compiled from thousands of health care providers, labs and other sources. Some public health experts say the Google data could help accelerate the response of doctors, hospitals and public health officials to a nasty flu season, reducing the spread of the disease and, potentially, saving lives.
“The earlier the warning, the earlier prevention and control measures can be put in place, and this could prevent cases of influenza,” said Dr. Lyn Finelli, lead for surveillance at the influenza division of the C.D.C. From 5 to 20 percent of the nation’s population contracts the flu each year, she said, leading to roughly 36,000 deaths on average.
The service covers only the United States, but Google is hoping to eventually use the same technique to help track influenza and other diseases worldwide.
“From a technological perspective, it is the beginning,” said Eric E. Schmidt, Google’s chief executive.
The premise behind Google Flu Trends — what appears to be a fruitful marriage of mob behavior and medicine — has been validated by an unrelated study indicating that the data collected by Yahoo, Google’s main rival in Internet search, can also help with early detection of the flu.
“In theory, we could use this stream of information to learn about other disease trends as well,” said Dr. Philip M. Polgreen, assistant professor of medicine and epidemiology at the University of Iowa and an author of the study based on Yahoo’s data.
Still, some public health officials note that many health departments already use other approaches, like gathering data from visits to emergency rooms, to keeping daily tabs on disease trends in their communities.
“We don’t have any evidence that this is more timely than our emergency room data,” said Dr. Farzad Mostashari, assistant commissioner of the Department of Health and Mental Hygiene in New York City.
If Google provided health officials with details of the system’s workings so that it could be validated scientifically, the data could serve as an additional, free way to detect influenza, said Dr. Mostashari, who is also chairman of the International Society for Disease Surveillance.
A paper on the methodology of Google Flu Trends is expected to be published in the journal Nature.
Researchers have long said that the material published on the Web amounts to a form of “collective intelligence” that can be used to spot trends and make predictions.
But the data collected by search engines is particularly powerful, because the keywords and phrases that people type into them represent their most immediate intentions. People may search for “Kauai hotel” when they are planning a vacation and for “foreclosure” when they have trouble with their mortgage. Those queries express the world’s collective desires and needs, its wants and likes.
Internal research at Yahoo suggests that increases in searches for certain terms can help forecast what technology products will be hits, for instance. Yahoo has begun using search traffic to help it decide what material to feature on its site.
Two years ago, Google began opening its search data trove through Google Trends, a tool that allows anyone to track the relative popularity of search terms. Google also offers more sophisticated search traffic tools that marketers can use to fine-tune ad campaigns. And internally, the company has tested the use of search data to reach conclusions about economic, marketing and entertainment trends.
“Most forecasting is basically trend extrapolation,” said Hal Varian, Google’s chief economist. “This works remarkably well, but tends to miss turning points, times when the data changes direction. Our hope is that Google data might help with this problem.”
Prabhakar Raghavan, who is in charge of Yahoo Labs and the company’s search strategy, also said search data could be valuable for forecasters and scientists, but privacy concerns had generally stopped it from sharing it with outside academics.
Google Flu Trends avoids privacy pitfalls by relying only on aggregated data that cannot be traced to individual searchers. To develop the service, Google’s engineers devised a basket of keywords and phrases related to the flu, including thermometer, flu symptoms, muscle aches, chest congestion and many others.
Google then dug into its database, extracted five years of data on those queries and mapped it onto the C.D.C.’s reports of influenzalike illness. Google found a strong correlation between its data and the reports from the agency, which advised it on the development of the new service.
“We know it matches very, very well in the way flu developed in the last year,” said Dr. Larry Brilliant, executive director of Google.org. Dr. Finelli of the C.D.C. and Dr. Brilliant both cautioned that the data needed to be monitored to ensure that the correlation with flu activity remained valid.
Google also says it believes the tool may help people take precautions if a disease is in their area.
Others have tried to use information collected from Internet users for public health purposes. A Web site called whoissick.org, for instance, invites people to report what ails them and superimposes the results on a map. But the site has received relatively little traffic.
HealthMap, a project affiliated with the Children’s Hospital Boston, scours the Web for articles, blog posts and newsletters to create a map that tracks emerging infectious diseases around the world. It is backed by Google.org, which counts the detection and prevention of diseases as one of its main philanthropic objectives.
But Google Flu Trends appears to be the first public project that uses the powerful database of a search engine to track a disease.
“This seems like a really clever way of using data that is created unintentionally by the users of Google to see patterns in the world that would otherwise be invisible,” said Thomas W. Malone, a professor at the Sloan School of Management at M.I.T. “I think we are just scratching the surface of what’s possible with collective intelligence.”A version of this article appeared in print on November 12, 2008, on page A1 of the New York edition.
Sunday, September 14, 2008

Tuesday, May 20, 2008
Nosso Amigo em Kathmandu
Como quase tudo na minha vida, meu gosto por sites é fortemente influenciado (contaminado?) pelos meus interesses e minha vida profissional – não sou muito bom em separar vida pessoal e profissional. Talvez por isso, um site em que sou bem ativo é o www.ask500people.com.
O Ask500People é um site de pesquisas ininterruptas, pela Internet. Você e dezenas de outras pessoas postam perguntas de múltipla escolha, que vão recebendo votos dos usuários, como você. As perguntas mais votadas vão subindo na “fila”, até que são “lançadas”. Então, pessoas de todo o mundo começam a responder à sua pergunta. Mais recentemente, passou a ser possível votar nas perguntas, enquanto elas ainda estão na fila.
Eu acho a coisa muito cool – você bola uma pergunta, pessoas julgam se ela é interessante, sua pergunta vai “ao ar” e centenas de pessoas ao redor do mundo tiram a dúvida que você tinha sobre como elas são, o que elas pensam, sentem, desejam, temem. Eu já teria ficado viciado na brincadeira, se a primeira versão beta do site não fosse bastante lenta. Agora não é mais e o risco de que eu gaste muitas preciosas horas de meus finais de semana ou noites, brincando de perguntar coisas às pessoas aumentou.
Outra coisa que melhorou muito é o número de respostas. Apesar dos 500, do nome, no começo a votação se encerrava quando chegava a 100 respostas. Agora, com a progressiva popularização do site, muitas perguntas estão chegando perto de receber as 500 respostas desejadas.
Além da real limitação do tamanho da amostra, no começo, eu também desconfiava do perfil dos respondentes: “Humm...”, eu pensava. “Com certeza, amostra viezada – deve ser uma garotada, ou uns computer geeks”. Então postei a pergunta: “Como você se define?”.
Surpresa: 56% dos usuários, ao redor do mundo, têm mais de 30 anos. Heavy-users de Internet, realmente são: 71%. Mas, mesmo entre esses, 62% têm mais de 30 anos.
OK. Então são pessoas maduras, bastante conectadas à Web. Minha próxima pergunta foi mais ousada: “Eu...
...nunca me encontrei com alguém que conheci através da Internet” – 44%
...me encontrei com várias pessoas que conheci via Internet” – 27%
...fiz sexo com alguém que conheci na Internet” – 19%
...casei com alguém que conheci na Internet” – 10%
Uau! Um em cada dez casou-se com alguém que conheceu via Web! Considerando que 32% dos usuários não são casados (segundo verifiquei por outras perguntas), na verdade o número de “casados via web”, entre os casados, é praticamente 1 em cada 7. Será verdade?
Consultando o livro “Microtrends”, do especialista em pesquisas americano Mark J. Penn, descubro (no capítulo “Internet Marrieds”!) que cerca de um em cada 43 casamentos americanos, realizados em 2007, foram de casais que se conheceram pela Web. Se o número de casais-web estiver dobrando a cada ano, há mais um casal, nesses 43, casado antes de 2007. Isso nos leva a um número de 1 casal-web em cada 21 ou 22 casais americanos. Um em cada 7 a 10, na população dos usuários Ask500People não parece, portanto, desarrazoado.
Não que o pessoal seja todo americano. A maioria é, principalmente nas perguntas que “vão ao ar” em horários em que a Europa está dormindo, quando as respostas de americanos podem chegar a quase 80%. E as diferenças nas respostas de diferentes países, como não podia deixar de ser, muitas vezes são marcantes.
Por exemplo, certa vez perguntei: “Você tem que escolher entre dois vinhos, de mesmo preço e da mesma variedade (digamos, Merlot). Qual você escolhe? Um excelente vinho, de um grande produtor global, ou um vinho muito bom (mas não excelente), de um produtor tradicional, de terroir”.
Como era de se esperar, todos os franceses e alemães disseram que escolheriam o vinho de terroir. Americanos e ingleses foram menos unânimes, mas cerca de 55% também escolheriam o vinho tradicional. Já na India, a tendência é oposta: dois terços prefeririam o “vinhão” globalizado. Já em países como Canadá, Egito e Arábia Saudita, o pessoal radicaliza: todos os respondentes escolheriam o “vinhão”. Talvez o pessoal desses países, de clima também “radical”, não tenham muito apreço pela idéia de “terroir”.
Uma outra pergunta (essa não foi minha) que também revelou diferenças regionais interessantes foi: “Você é mais cândido com alguns amigos on-line, do que com seu/sua melhor amigo(a), parceiro(a) ou esposa(o)?”.
Mais de 70% dos americanos, franceses e canadenses e mais de 60% dos ingleses e japoneses disseram que não (algo me diz que, os franceses, por uma razão diferente dos demais...). Os coreanos ficaram no meio-a-meio. Nós, brasileiros, nossos vizinhos argentinos e os italianos já viramos para o outro lado: cerca de 60% de nós “nos abrimos” mais on-line do que ao vivo. Aí os mexicanos, marroquinos, argerianos e outros “vão para as cabeças” – 90% a 100% soltam a língua, mesmo, é na web.
E o que esse universo de interneteiros globais, maduros mas modernos, de idéias liberais mas comportamento um tanto conservador, pensa do Brasil? Perguntei (e essa foi minha pergunta que recebeu mais votos, para “ir ao ar”): “Brasil é...
...um país significativo, no concerto das nações (redação deliberadamente pretenciosa) – espantosos (pelo menos para mim) 48% optaram por essa resposta.
Em compensação, 37% responderam que “não têm idéia do que é ou onde fica o Brasil” (13%), ou que “o Brasil é um país marginal e sem importância” (24%).
E os 15% restantes? Esses responderam que o Brasil “é um lugar onde gostariam de viver”.
Apesar de um terço dos coreanos desejar viver no Brasil, metade não sabe onde ficamos e o restante nos considera um país sem importância. Já a metade dos canadenses e australianos – e 51% dos americanos – nos consideram muito importantes (o único argentino que respondeu, também).
E, então, tem essa pessoa em Kathmandu, no Nepal. Será um homem? Uma mulher? Não tenho como saber, mas uma coisa eu sei: ele ou ela gostaria de viver no Brasil.
Friday, November 24, 2000
The Screen People of Tomorrow (cont.)
An emerging set of cheap tools is now making it easy to create digital video. There were more than 10 billion views of video on YouTube in September. The most popular videos were watched as many times as any blockbuster movie. Many are mashups of existing video material. Most vernacular video makers start with the tools of Movie Maker or iMovie, or with Web-based video editing software like Jumpcut. They take soundtracks found online, or recorded in their bedrooms, cut and reorder scenes, enter text and then layer in a new story or novel point of view. Remixing commercials is rampant. A typical creation might artfully combine the audio of a Budweiser “Wassup” commercial with visuals from “The Simpsons” (or the Teletubbies or “Lord of the Rings”). Recutting movie trailers allows unknown auteurs to turn a comedy into a horror flick, or vice versa.
Rewriting video can even become a kind of collective sport. Hundreds of thousands of passionate anime fans around the world (meeting online, of course) remix Japanese animated cartoons. They clip the cartoons into tiny pieces, some only a few frames long, then rearrange them with video editing software and give them new soundtracks and music, often with English dialogue. This probably involves far more work than was required to edit the original cartoon but far less work than editing a clip a decade ago. The new videos, called Anime Music Videos, tell completely new stories. The real achievement in this subculture is to win the Iron Editor challenge. Just as in the TV cookoff contest “Iron Chef,” the Iron Editor must remix videos in real time in front of an audience while competing with other editors to demonstrate superior visual literacy. The best editors can remix video as fast as you might type.
In fact, the habits of the mashup are borrowed from textual literacy. You cut and paste words on a page. You quote verbatim from an expert. You paraphrase a lovely expression. You add a layer of detail found elsewhere. You borrow the structure from one work to use as your own. You move frames around as if they were phrases.
Digital technology gives the professional a new language as well. An image stored on a memory disc instead of celluloid film has a plasticity that allows it to be manipulated as if the picture were words rather than a photo. Hollywood mavericks like George Lucas have embraced digital technology and pioneered a more fluent way of filmmaking. In his “Star Wars” films, Lucas devised a method of moviemaking that has more in common with the way books and paintings are made than with traditional cinematography.
In classic cinematography, a film is planned out in scenes; the scenes are filmed (usually more than once); and from a surfeit of these captured scenes, a movie is assembled. Sometimes a director must go back for “pickup” shots if the final story cannot be told with the available film. With the new screen fluency enabled by digital technology, however, a movie scene is something more flexible: it is like a writer’s paragraph, constantly being revised. Scenes are not captured (as in a photo) but built up incrementally. Layers of visual and audio refinement are added over a crude outline of the motion, the mix constantly in flux, always changeable. George Lucas’s last “Star Wars” movie was layered up in this writerly way. He took the action “Jedis clashing swords — no background” and laid it over a synthetic scene of a bustling marketplace, itself blended from many tiny visual parts. Light sabers and other effects were digitally painted in later, layer by layer. In this way, convincing rain, fire and clouds can be added in additional layers with nearly the same kind of freedom with which Lucas might add “it was a dark and stormy night” while writing the script. Not a single frame of the final movie was left untouched by manipulation. In essence, a digital film is written pixel by pixel.The recent live-action feature movie “Speed Racer,” while not a box-office hit, took this style of filmmaking even further. The spectacle of an alternative suburbia was created by borrowing from a database of existing visual items and assembling them into background, midground and foreground. Pink flowers came from one photo source, a bicycle from another archive, a generic house roof from yet another. Computers do the hard work of keeping these pieces, no matter how tiny and partial they are, in correct perspective and alignment, even as they move. The result is a film assembled from a million individual existing images. In most films, these pieces are handmade, but increasingly, as in “Speed Racer,” they can be found elsewhere.
In the great hive-mind of image creation, something similar is already happening with still photographs. Every minute, thousands of photographers are uploading their latest photos on the Web site Flickr. The more than three billion photos posted to the site so far cover any subject you can imagine; I have not yet been able to stump the site with a request. Flickr offers more than 200,000 images of the Golden Gate Bridge alone. Every conceivable angle, lighting condition and point of view of the Golden Gate Bridge has been photographed and posted. If you want to use an image of the bridge in your video or movie, there is really no reason to take a new picture of this bridge. It’s been done. All you need is a really easy way to find it.
Similar advances have taken place with 3D models. On Google SketchUp’s 3D Warehouse, you can find insanely detailed three-dimensional virtual models of most major building structures of the world. Need a street in San Francisco? Here’s a filmable virtual set. With powerful search and specification tools, high-resolution clips of any bridge in the world can be circulated into the common visual dictionary for reuse. Out of these ready-made “words,” a film can be assembled, mashed up from readily available parts. The rich databases of component images form a new grammar for moving images.
After all, this is how authors work. We dip into a finite set of established words, called a dictionary, and reassemble these found words into articles, novels and poems that no one has ever seen before. The joy is recombining them. Indeed it is a rare author who is forced to invent new words. Even the greatest writers do their magic primarily by rearranging formerly used, commonly shared ones. What we do now with words, we’ll soon do with images.
For directors who speak this new cinematographic language, even the most photo-realistic scenes are tweaked, remade and written over frame by frame. Filmmaking is thus liberated from the stranglehold of photography. Gone is the frustrating method of trying to capture reality with one or two takes of expensive film and then creating your fantasy from whatever you get. Here reality, or fantasy, is built up one pixel at a time as an author would build a novel one word at a time. Photography champions the world as it is, whereas this new screen mode, like writing and painting, is engineered to explore the world as it might be.
But merely producing movies with ease is not enough for screen fluency, just as producing books with ease on Gutenberg’s press did not fully unleash text. Literacy also required a long list of innovations and techniques that permit ordinary readers and writers to manipulate text in ways that make it useful. For instance, quotation symbols make it simple to indicate where one has borrowed text from another writer. Once you have a large document, you need a table of contents to find your way through it. That requires page numbers. Somebody invented them (in the 13th century). Longer texts require an alphabetic index, devised by the Greeks and later developed for libraries of books. Footnotes, invented in about the 12th century, allow tangential information to be displayed outside the linear argument of the main text. And bibliographic citations (invented in the mid-1500s) enable scholars and skeptics to systematically consult sources. These days, of course, we have hyperlinks, which connect one piece of text to another, and tags, which categorize a selected word or phrase for later sorting.All these inventions (and more) permit any literate person to cut and paste ideas, annotate them with her own thoughts, link them to related ideas, search through vast libraries of work, browse subjects quickly, resequence texts, refind material, quote experts and sample bits of beloved artists. These tools, more than just reading, are the foundations of literacy.
If text literacy meant being able to parse and manipulate texts, then the new screen fluency means being able to parse and manipulate moving images with the same ease. But so far, these “reader” tools of visuality have not made their way to the masses. For example, if I wanted to visually compare the recent spate of bank failures with similar events by referring you to the bank run in the classic movie “It’s a Wonderful Life,” there is no easy way to point to that scene with precision. (Which of several sequences did I mean, and which part of them?) I can do what I just did and mention the movie title. But even online I cannot link from this sentence to those “passages” in an online movie. We don’t have the equivalent of a hyperlink for film yet. With true screen fluency, I’d be able to cite specific frames of a film, or specific items in a frame. Perhaps I am a historian interested in oriental dress, and I want to refer to a fez worn by someone in the movie “Casablanca.” I should be able to refer to the fez itself (and not the head it is on) by linking to its image as it “moves” across many frames, just as I can easily link to a printed reference of the fez in text. Or even better, I’d like to annotate the fez in the film with other film clips of fezzes as references.
With full-blown visuality, I should be able to annotate any object, frame or scene in a motion picture with any other object, frame or motion-picture clip. I should be able to search the visual index of a film, or peruse a visual table of contents, or scan a visual abstract of its full length. But how do you do all these things? How can we browse a film the way we browse a book?
It took several hundred years for the consumer tools of text literacy to crystallize after the invention of printing, but the first visual-literacy tools are already emerging in research labs and on the margins of digital culture. Take, for example, the problem of browsing a feature-length movie. One way to scan a movie would be to super-fast-forward through the two hours in a few minutes. Another way would be to digest it into an abbreviated version in the way a theatrical-movie trailer might. Both these methods can compress the time from hours to minutes. But is there a way to reduce the contents of a movie into imagery that could be grasped quickly, as we might see in a table of contents for a book?
Academic research has produced a few interesting prototypes of video summaries but nothing that works for entire movies. Some popular Web sites with huge selections of movies (like porn sites) have devised a way for users to scan through the content of full movies quickly in a few seconds. When a user clicks the title frame of a movie, the window skips from one key frame to the next, making a rapid slide show, like a flip book of the movie. The abbreviated slide show visually summarizes a few-hour film in a few seconds. Expert software can be used to identify the key frames in a film in order to maximize the effectiveness of the summary.
The holy grail of visuality is to search the library of all movies the way Google can search the Web. Everyone is waiting for a tool that would allow them to type key terms, say “bicycle + dog,” which would retrieve scenes in any film featuring a dog and a bicycle. In an instant you could locate the moment in “The Wizard of Oz” when the witchy Miss Gulch rides off with Toto. Google can instantly pinpoint desirable documents out of billions on the Web because computers can read text, but computers are only starting to learn how to read images.It is a formidable task, but in the past decade computers have gotten much better at recognizing objects in a picture than most people realize. Researchers have started training computers to recognize a human face. Specialized software can rapidly inspect a photograph’s pixels searching for the signature of a face: circular eyeballs within a larger oval, shadows that verify it is spherical. Once an algorithm has identified a face, the computer could do many things with this knowledge: search for the same face elsewhere, find similar-looking faces or substitute a happier version.
Of course, the world is more than faces; it is full of a million other things that we’d like to have in our screen vocabulary. Currently, the smartest object-recognition software can detect and categorize a few dozen common visual forms. It can search through Flickr photos and highlight the images that contain a dog, a cat, a bicycle, a bottle, an airplane, etc. It can distinguish between a chair and sofa, and it doesn’t identify a bus as a car. But each additional new object to be recognized means the software has to be trained with hundreds of samples of that image. Still, at current rates of improvement, a rudimentary visual search for images is probably only a few years away.
What can be done for one image can also be done for moving images. Viewdle is an experimental Web site that can automatically identify select celebrity faces in video. Hollywood postproduction companies routinely “read” sequences of frames, then “rewrite” their content. Their custom software permits human operators to eradicate wires, backgrounds, unwanted people and even parts of objects as these bits move in time simply by identifying in the first frame the targets to be removed and then letting the machine smartly replicate the operation across many frames.
The collective intelligence of humans can also be used to make a film more accessible. Avid fans dissect popular movies scene by scene. With maniacal attention to detail, movie enthusiasts will extract bits of dialogue, catalog breaks in continuity, tag appearances of actors and track a thousand other traits. To date most fan responses appear in text form, on sites like the Internet Movie Database. But increasingly fans respond to video with video. The Web site Seesmic encourages “video conversations” by enabling users to reply to one video clip with their own video clip. The site organizes the sprawling threads of these visual chats so that they can be read like a paragraph of dialogue.
The sheer number of user-created videos demands screen fluency. The most popular viral videos on the Web can reach millions of downloads. Success garners parodies, mashups or rebuttals — all in video form as well. Some of these offspring videos will earn hundreds of thousands of downloads themselves. And the best parodies spawn more parodies. One site, TimeTube, offers a genealogical view of the most popular videos and their descendants. You can browse a time line of all the videos that refer to an original video on a scale that measures both time and popularity. TimeTube is the visual equivalent of a citation index; instead of tracking which scholarly papers cite other papers, it tracks which videos cite other videos. All of these small innovations enable a literacy of the screen.
As moving images become easier to create, easier to store, easier to annotate and easier to combine into complex narratives, they also become easier to be remanipulated by the audience. This gives images a liquidity similar to words. Fluid images made up of bits flow rapidly onto new screens and can be put to almost any use. Flexible images migrate into new media and seep into the old. Like alphabetic bits, they can be squeezed into links or stretched to fit search engines, indexes and databases. They invite the same satisfying participation in both creation and consumption that the world of text does.
We are people of the screen now. Last year, digital-display manufacturers cranked out four billion new screens, and they expect to produce billions more in the coming years. That’s one new screen each year for every human on earth. With the advent of electronic ink, we will start putting watchable screens on any flat surface. The tools for screen fluency will be built directly into these ubiquitous screens.
With our fingers we will drag objects out of films and cast them in our own movies. A click of our phone camera will capture a landscape, then display its history, which we can use to annotate the image. Text, sound, motion will continue to merge into a single intermedia as they flow through the always-on network. With the assistance of screen fluency tools we might even be able to summon up realistic fantasies spontaneously. Standing before a screen, we could create the visual image of a turquoise rose, glistening with dew, poised in a trim ruby vase, as fast as we could write these words. If we were truly screen literate, maybe even faster. And that is just the opening scene.Kevin Kelly is senior maverick at Wired and the author of “Out of Control” and a coming book on what technology wants.
Subscribe to:
Comments (Atom)